Java Data Mining Package
A Library for Machine Learning and Big Data Analytics
The Java Data Mining Package (JDMP) is an open source Java library for data analysis and machine learning. It facilitates the access to data sources and machine learning algorithms (e.g. clustering, regression, classification, graphical models, optimization) and provides visualization modules. JDMP provides a number of algorithms and tools, but also interfaces to other machine learning and data mining packages (Weka, LibLinear, Elasticsearch, LibSVM, Mallet, Lucene, Octave).
In a Nutshell
- Includes many machine learning algorithms
- Easy interface for data sets and algorithms
- Multi-threaded and lighting fast
- Handle terabyte-sized data
- Visualize and edit as heatmap, graph, plot
- Treat every type of data as a matrix
- TXT, CSV, PNG, JPG, HTML, XLS, XLSX, PDF, LaTeX, Matlab, MDB
- Free and open source (LGPL)
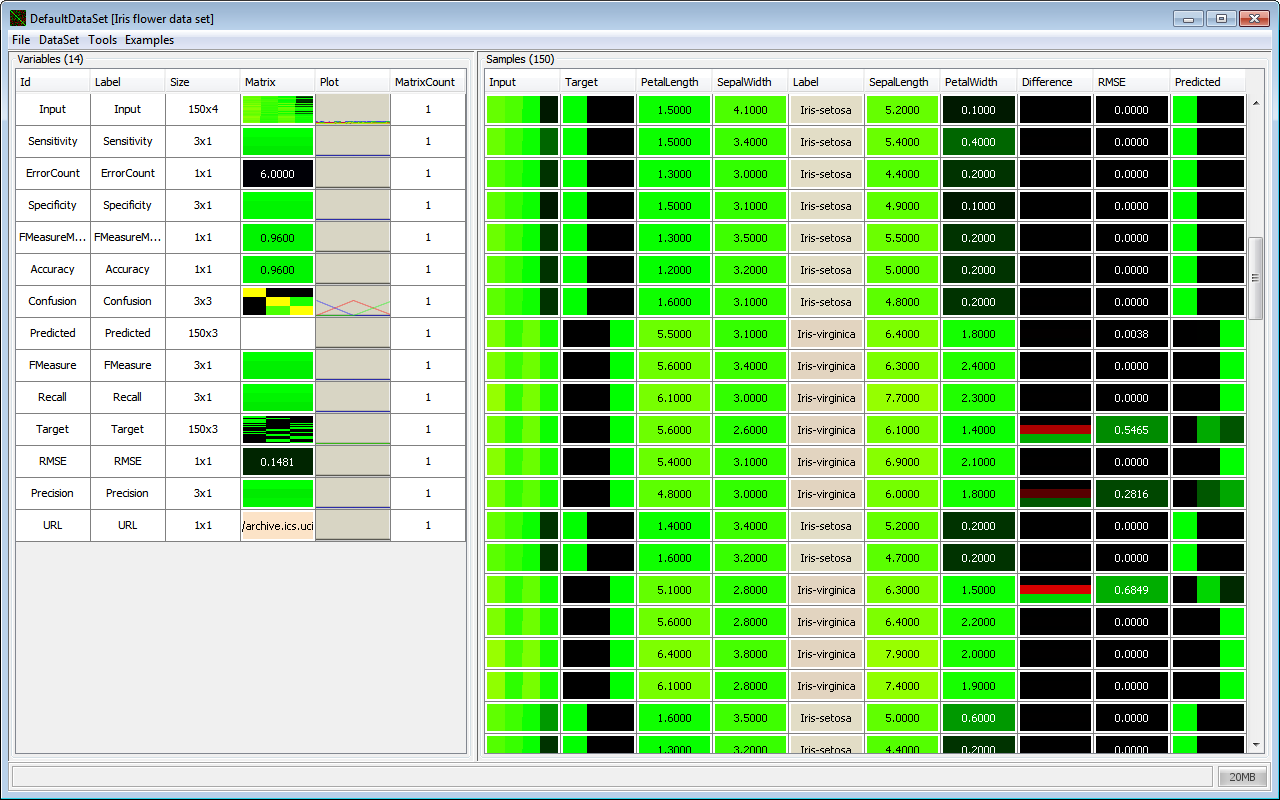
Screenshots
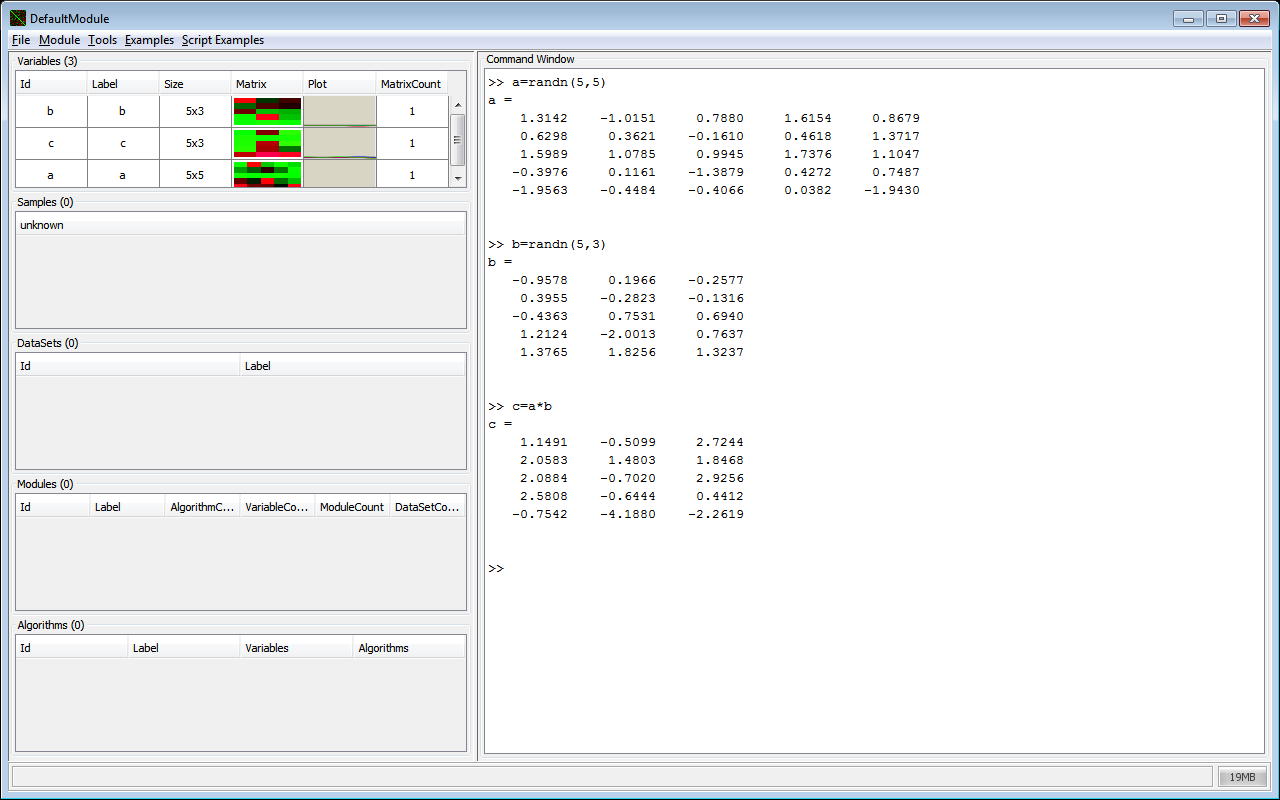
Features
The main focus of JDMP lies on a consistent data representation. Maybe you’ve heard that, for Linux everything is a file. For JDMP, everything is a Matrix! Well, not everything, but many objects do have a matrix representation. For example: you can combine several matrices to form a Variable, e.g. for a time series. You can access these matrices one by one, or as a single big matrix, whatever is more suitable for your task. Several Variables are combined into a Sample, like the samples with input and target values in a classification task. Many Samples form a DataSet, which may be sorted or split for a cross validation test. The DataSet can be accesses either sample by sample or as a big matrix for the input features and one for the target values.
Algorithms can manipulate Variables, Samples or DataSets, e.g. to perform pre-processing or a classification task. It has to be emphasized that, in JDMP, data processing methods are separated from data sources, so that algorithms and data may reside on different computers and parallel processing becomes possible. However, distributed computing is not yet fully implemented and exists in a “proof of concept” version only.
While some parts are pretty stable by now, a lot of development is still going on in other parts, which is why JDMP has to be considered as experimental and not yet ready for production use.
Too good to be true?
Well, to be perfectly honest with you, there are some things you will not like about JDMP, so here is the list why you may not want to use it:
The Java Data Mining Package is...
-
...not finished
While some parts are already pretty stable, a lot of development is still going on in other areas. There is no guarantee that everything will be working as expected. Be prepared for renamed methods and interfaces from one version to the next. -
...not well documented
Since many things are going to change anyway, we didn't bother to write much documentation.
Wanna help?
Developers are welcome to contribute new features, test cases or documentation.
If you like this library and it does something useful for you, a small donation will be very much appreciated to help cover server costs and ensure the coffee supply for further development.
Thank you very much for supporting open source software!
Download
Include via Maven
The easiest way to add JDMP to your projects is to include it via Maven. You will need at least
the jdmp-core package which contains the basic algorithm classes and data sets.
Add these lines to the <dependencies> section in your
pom.xml file:
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-core</artifactId>
<version>0.3.0</version>
</dependency>
The jdmp-gui package is useful when you want to display datasets or algorithms on the screen:
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-gui</artifactId>
<version>0.3.0</version>
</dependency>
Other dependencies can be added as required using the appropriate sub-packages of JDMP. Here is the full list:
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-core</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-gui</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-bsh</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-complete</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-corenlp</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-examples</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-jetty</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-liblinear</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-libsvn</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-lucene</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-mallet</artifactId>
<version>0.3.0</version>
</dependency>
<dependency>
<groupId>org.jdmp</groupId>
<artifactId>jdmp-weka</artifactId>
<version>0.3.0</version>
</dependency>
Download JAR Packages
If you don't have Maven, you can download a jar file containing all jdmp packages here: jdmp-complete.jar
This package contains jdmp-core, the main part of the Java Data Mining Package, as well as
additional features such as visualization and interfaces to other libraries, and a lot more. If
you are new to this library, just invoke
the main() method in org.jdmp.gui.JDMP:
java -jar jdmp-complete.jar
Then click on "Tools - JDMP Plugins" in the menu bar and see what third party libraries are supported. Chose the tool you want, add the necessary dependencies to the class path and restart JDMP.
Download Source Code from GitHub
The source code of JDMP is available from GitHub. You can clone the repository like this:
git clone https://github.com/jdmp/java-data-mining-package.git
This is the link to the repository: JDMP on GitHub
You are welcome to contribute, just send me a pull request on GitHub.
Documentation
Quick Start
// load example data set
ListDataSet dataSet = DataSet.Factory.IRIS();
// create a classifier
NaiveBayesClassifier classifier = new NaiveBayesClassifier();
// train the classifier using all data
classifier.trainAll(dataSet);
// use the classifier to make predictions
classifier.predictAll(dataSet);
// get the results
double accuracy = dataSet.getAccuracy();
System.out.println("accuracy: " + accuracy);
Self-Organizing Map
// load example data set ListDataSet dataSet = DataSet.Factory.ANIMALS(); // create a self-organizing map SelfOrganizingMap som = new SelfOrganizingMap(); // train the SOM using all data som.trainAll(dataSet); // use the SOM to make predictions som.predictAll(dataSet); // display dataset on the screen dataSet.showGUI();
Show the Workspace
org.jdmp.gui.JDMP.main(args);
List of JDMP Modules
jdmp |
Parent package with just the master .pom file without any Java code | Module Info |
jdmp-bsh |
Plugin to incorporate BeanShell | Module Info API Docs |
jdmp-complete |
Collection of all available JDMP modules in one meta package | Module Info API Docs |
jdmp-core |
Main package of JDMP containing machine learning algorithms and functions | Module Info API Docs |
jdmp-corenlp |
Plugin to incorporate algorithms from Stanford CoreNLP | Module Info API Docs |
jdmp-examples |
Some simple examples how to use the Java Data Mining Package | Module Info API Docs |
jdmp-gui |
Plugin to enable visualization and graphics | Module Info API Docs |
jdmp-jetty |
Plugin to incorporate Jetty web server | Module Info API Docs |
jdmp-liblinear |
Plugin to incorporate classification algorithms from liblinear | Module Info API Docs |
jdmp-libsvm |
Plugin to incorporate classification algorithms from c | Module Info API Docs |
jdmp-lucene |
Plugin to enable text indexing using Apache Lucene | Module Info API Docs |
jdmp-mallet |
Plugin to incorporate text mining algorithms from Mallet | Module Info API Docs |
jdmp-weka |
Plugin to incorporate classification and clustering algorithms from Weka | Module Info API Docs |
Universal Java Matrix Package
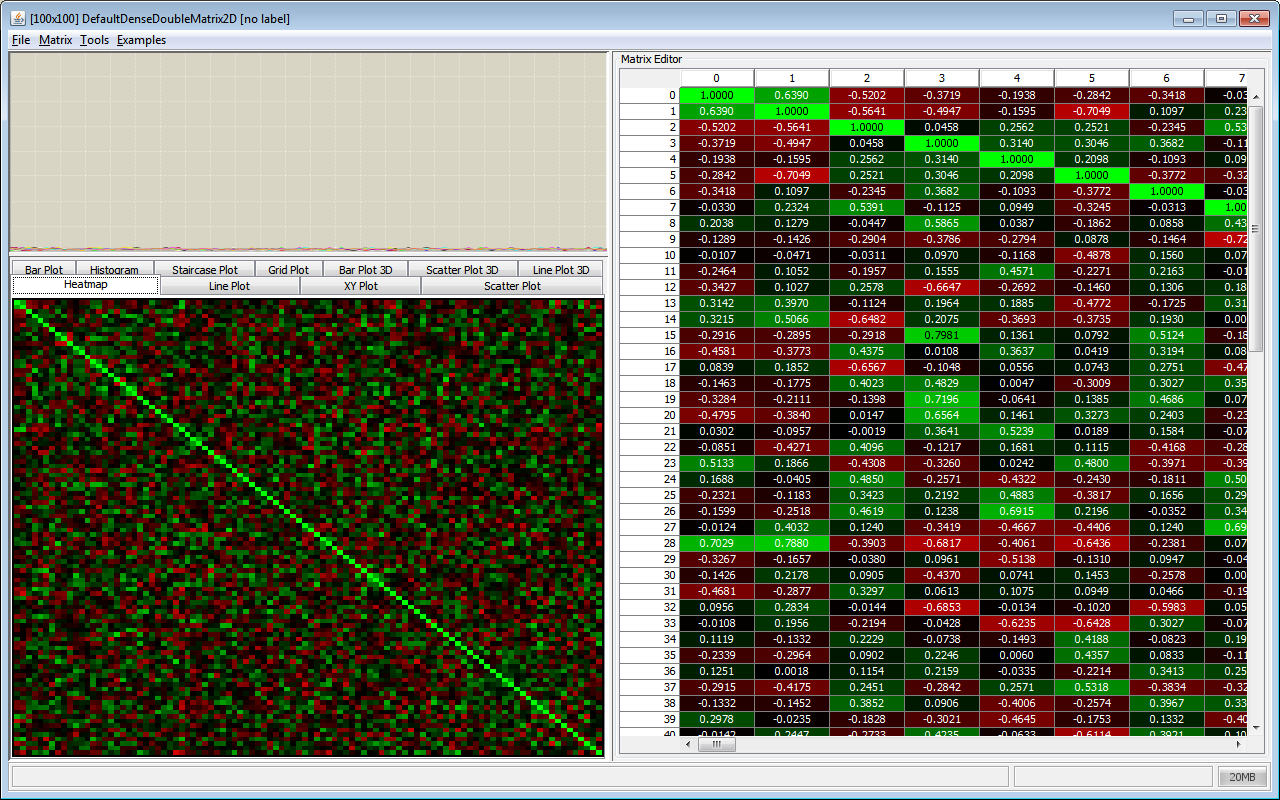
JDMP uses the Universal Java Matrix Package (UJMP) as a mathematical back-end for matrix calculations. UJMP provides most of JDMP's import and export filters and is used for visualization. Since most of JDMP's objects can be converted into a "matrix view", UJMP is a very important building block in JDMP and helps to keep the code nice and simple with the ability to handle very large matrices even when they do not fit into memory. Import and export interfaces are provided for JDBC data bases, TXT, CSV, Excel, Matlab, Latex, MTX, HTML, WAV, BMP and other file formats.
Contributors
Holger Arndt
Project manager, JDMP core package, JDMP GUI package, interfaces to other libraries
Holger's Homepage
Markus Bundschus
Strategical consultancy, marketing
Markus's
Homepage
Andreas Nägele
Naive Bayes Classifier, test cases